
Benchmark Screen
The Benchmark Screen consists of two tabs 'Standard' and 'Advanced'. The first allows one to run the benchmark with standard settings, whereas the second allows for a fine-grained customization of the settings. In the following we discuss the main GUI elements from top to bottom:
Device and Platform Selector
Select the OpenCL device from the respective OpenCL platform on which you want to run the benchmark. Note that CPUs might be supported by multiple OpenCL platforms and hence may show up multiple times in the list.
Benchmark Selector, Advanced Settings, Overall Results

The benchmark selector on the left allows for disabling selected benchmarks. Usually one wants to run the full set of benchmarks, but in some cases one may want to focus on a subgroup
- 'All' is a convenience button for selecting/deselecting all benchmarks.
- 'Blas3' is a shortcut for dense matrix-matrix multiplications.
- 'Copy' refers to a host-device bandwidth benchmark.
- 'Sparse' enables or disables the evaluation of sparse matrix-vector products.
- 'Vector' refers to vector operations and provides a STREAM-like benchmark to evaluate memory bandwidth.

[Advanced Tab only: The benchmark configuration setting allows you to set the minimum and maximum matrix and vector sizes used for the benchmark. The 'increment' factor denotes the factor between two sizes. For example, a matrix size of 128 with an increment factor of 2 leads to matrix dimensions 128, 256, 512, etc. used for the benchmark. For simplicity, all matrices used for the benchmark are square. The size for the sparse matrix is approximate: The actual matrix size is obtained from a 2d-discretization of a rectangular domain using 5-point finite differences. Consequently, the actual sparse matrix size might have a little larger or smaller, but differences are typically negligible in practice. To use your own sparse matrix, provide a Matrix-Market file via a click on 'Browse' in order to load it into the benchmark.]
The overall result plot on the right of the benchmark selector plots the best performances obtained for each of the three benchmarks. Typically the FLOPs measured for dense matrices is much higher than for sparse matrices. Similarly, the bandwidth for vector operations is higher than the host-device bandwidth represented by 'Copy'.
Precision Selector, Start Button, Progress Bar
Switch here between single (float) and double precision arithmetic. Some OpenCL devices do not provide support double precision arithmetic, in which case you will receive an error message.
Next to the precision selector is the 'Start' button, which starts (or stops) a benchmark.
The overall progress in the benchmark is visually displayed by the progress bar to the right.
Result Plots
The results for each of the four benchmarks are provided in the respective tab. Click on 'Toggle Fullscreen' to increase the plot size. A customization of the axes is currently not possible.
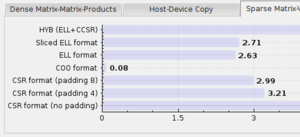
The matrix formats in the sparse matrix vector products are as follows:
- CSR format: Compressed row storage (example). The padding refers to potentially adding zeros to each row of the matrix so that the number of nonzeros per row is a multiple of the 'padding' parameter. The three CSR formats refer to the ViennaCL types compressed_matrix<T> (using an CSR-adaptive kernel), compressed_matrix<T, 4>, and compressed_matrix<T, 8>, respectively.
- COO format: Coordinate list storage (example). Often the slowest format for massively parallel hardware. coordinate_matrix<T> in ViennaCL.
- ELL format: ELLPACK format (paper with example). Implemented as ell_matrix<T> in ViennaCL.
- Sliced ELL format: Modified ELLPACK format proposed by Kreutzer et al. (preprint). Implemented in ViennaCL as sliced_ell_matrix<T> (currently without sorting).
- Hybrid format: Uses the ELLPACK format with a reduced number of entries per row. Remaining entries are stored using a modified (compressed) CSR format where only rows with nonzeros are stored.